
It’s been quite a long time since my last post for my blog. But that has been because of a specific reason: I participated at the 2nd DFB Hackathon, which consumed a huge amount of my freetime, which I normally spent creating some content for my blog. The Hackathon was again a great experience as all this deep data science stuff is still a challenge for me. But there’s again on big question on my side: Why are data scientist often just using Python (or R) and don’t know, how and when to use SQL.
The 2nd DFB Hackathon
To provide at first some context, I want to share some information about the DFB Hackathon. The 1st one was a really small one, which just happend over the period of 2 days. The 2nd was now based on the key facts: more time, more data, more re-usable results. We were provided 2 seasons of Bundesliga position data and different challenges, which should be solved over a period of 6 months. A extension was cause by all the COVID problems. My team had the task to create a throw-in model, to measure the risk and reward of throw-ins in football. For everybody already aware of, how such models are created: we used a similar approach like for expected goal models. Based on huge amount features for the specific match situation, a machine learning algorithm determines the expected risk or reward for specific throw-in execution.
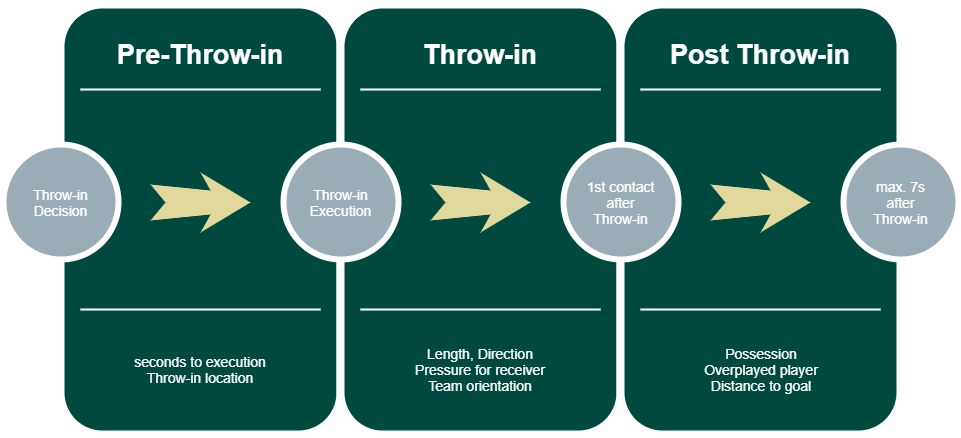
But explaining the detailed implementation is not my goal for this post. I want to suggest something, from my view as a data engineer: Every professional data scientist should know SQL!
The advantages of SQL
Already during the 1st Hackathon I recognized, the data scientist exchanged Python scripts and packages, which should made their life easier during the Hackathon. And I asked myself: Why are they trying to achieve everything with Python? A single football match contains about 3.6 million data points of positional data. Why are they not using SQL? A data scientist I am currently working with, also couldn’t really answer this question, while he admits, it my be a good idea to take a look at SQL.
While starting working in data analytics more than 15 years ago, I learned SQL as my go-to tool, when it’s about getting insights from data. And that’s because of some simple reasons:
It’s a query language
Huge amounts of data are normally maintained in databases. And SQL in comparison to Python is a query language, which is directly aimed to extract data from relational databases. It’s not a universal programming language, but it helps to work in an easy way with database.
Small grammer
As a language SQL is simpler than Python. It has a smaller grammer and the amount of different concepts is smaller. So it’s easy to get started. But in my opinion it’s still not easier to master. Therefor you also need a understanding of data, data modeling and how it’s organized inside a relational database. As a 2nd advantage a smaller grammer makes SQL easier to understand. SQL code is also easier to maintain.
Speed
SQL code is executed inside a database. And modern database provides the possibility to have indexes and partitions for your data, to provide faster access. So you will get your results way faster, when working with SQL in comparison to Python scripts. Manipulating data with Python requires multiple steps. Data is unloaded from the database or a file. The manupulation is done inside a script and afterwords it need to be written back into the database or another file.
Filtering and aggregation
SQL excels definitely in one area: Filtering and aggregating data. 4 lines of code are already enough to have a basic aggregation containing a filter. Anybody might argue, but such basic operations are most of the time already enough to fullfill needed business requirements.
SQL vs. Pandas
With the introduction of Pandas many SQL-like operations were now also easily possible on data frames in Python. This small articel provides a great comparison for some simple operations:
TowardsDataScience: SQL vs Python
So you might think: Ok, so I can stay using Python. But there are some more advanced topics you should think about, where Pandas data frame operations seem not to be the best solution.


Data movement
The data you are working with, might not only be consumed by you, but multiple other colleagues. So the data is part of a broader workflow and may be consumed by e.g. a BI Tool. And that’s where SQL is needed as this is the most common and standarderized way of different visualization tools to enter data.
Analytical- & Window-functions
One of my personal killer criterias for SQL are analytical functions and window functions. When working with time-series data, these functions make your life a lot easier. You want to have the start and end position of a player during a defined time frame? FIRST_VALUE and LAST_VALUE provide you the posibility. You need to determine the ball status in the previous or next frame? LEAD and LAG is the answer. Also window aggregations like a moving average a fairly simple. You just need to add a WINDOW clause to your basic aggregation. And everything still within one line of code. Using Python you would need to loop over the different partitions and store intermediate value and handle the results.
Disadvantages of SQL
But of course there are two sides to every coin: SQL has also limitations and is not usable for every use-case.
Missing SQL functions
When using SQL extensively when transforming data, you will immediately notice some functionality limitations. The SQL standard and the different vendor implementations often miss some specialized functions. For general functions e.g. text transformation you will find a huge selection of functions. But fortunately that’s no reason to overboard SQL. Each database vendor provides the possibility to extend their SQL standard with user defined functions. And on top you often also have the possibility to use different programming languages (e.g. Python, JavaScript, R) and take advantage of the different languages functionalities.

It’s a query langugae
What’s the first advantage of SQL, will also be our last disadvantage in this list: SQL is a query language. So it’s limited to work with data. But when thinking about one of the main tasks of a data scientist – creating models – that’s just not possible. In such cases you are restricted to the capabilites of a universal programming language like Python.
Conclusion
An underestimated part in the daily work of a data scientist is handling data: loading, unloading, transforming, wrangling. I know, it will not take long, till I meet the next data scientist, who is doing this stuff in a Python script. And it will be again the time, where I am giving a small advice from my perspective as a data engineer: Take a look at SQL!

One Reply to “”