
How does my typical betting weekend looks like, when I start ckecking, whether there are some interesting matches? I start my laptop, open the browser, start my Python program, start the database and after some minutes, I am able to start my data prcoessing, which collects all the data and calculates the predictions. That’s already great, but wouldn’t it be even better to have all predictions always already up-to-date? This blog will show you how to setup and run a small automated data pipeline in AWS, which extracts all stats from Understat.com.
AWS cloud services
Having an automated daily calculation normally requires separate hardware and additional maintenance effort to manage the OS and all applications. Fortunately AWS offers multiple Software-as-a-Service (SaaS) solutions, which don’t need any kind of administration and can be used directly. That safes you not only a huge amount of time, you are also not spending much money, as you just pay the time you are using the services.
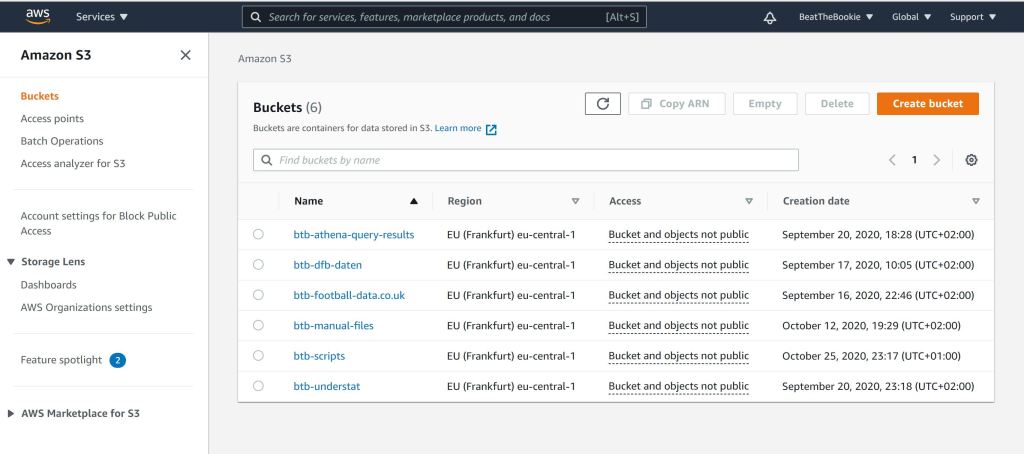
For this example 4 different AWS Services are used:
AWS S3 – A basic object storage of nearly every AWS service. This is used to store all data files, processing & model results.
AWS Glue – AWS Glue offers multiple features to support you, when building a data pipeline. Glue Data Catalog is used to build a meta catalog for all data files. For processing your data, Glue Jobs and Glue Workflows can be used.
AWS Athena – I am a fan of using as much SQL as possible, while working with structured data. Athena is the AWS query service, which allows you to query data stored on S3 in single files with SQL.
Extracting Understat.com data
In an older blog series I already used Understat.com data to take a look add xG data. At this time I used BeautifulSoap to scrap the data manual from the website. This was a really slow solution. Fortunately I found the Understat python packages, which helps you to easily extract the data from the website.
async def main():
async with aiohttp.ClientSession() as session:
understat = Understat(session)
fixtures = await understat.get_league_fixtures(
"epl",
2018,
{
"h": {"id": "89",
"title": "Manchester United",
"short_title": "MUN"}
}
)
print(json.dumps(fixtures))
loop = asyncio.get_event_loop()
loop.run_until_complete(main())The package offers multiple functions, which can be used to get the data from different parts of the website. I mainly focused on 5 functions:
- Fixtures
- Results
- Match player stats
- Match shots
- Team stats
These functions are enough to get all base data from understat. All other functions provide the same data just from another view or in an aggregated way. Player shots for example provides all shots for a single player. But that’s exactly the same data as match shots, just grouped by the player.
Define storage structure
One of the first steps should be to define the AWS S3 bucket structure, where all the single files of the extraction jobs will be stored. It’s up to the personal preference to create such a structure. I decide to have on single bucket for each data provider and differ between the datasets in different directories. The understat bucket contains one directory for each of the mentioned Python understat interfaces.
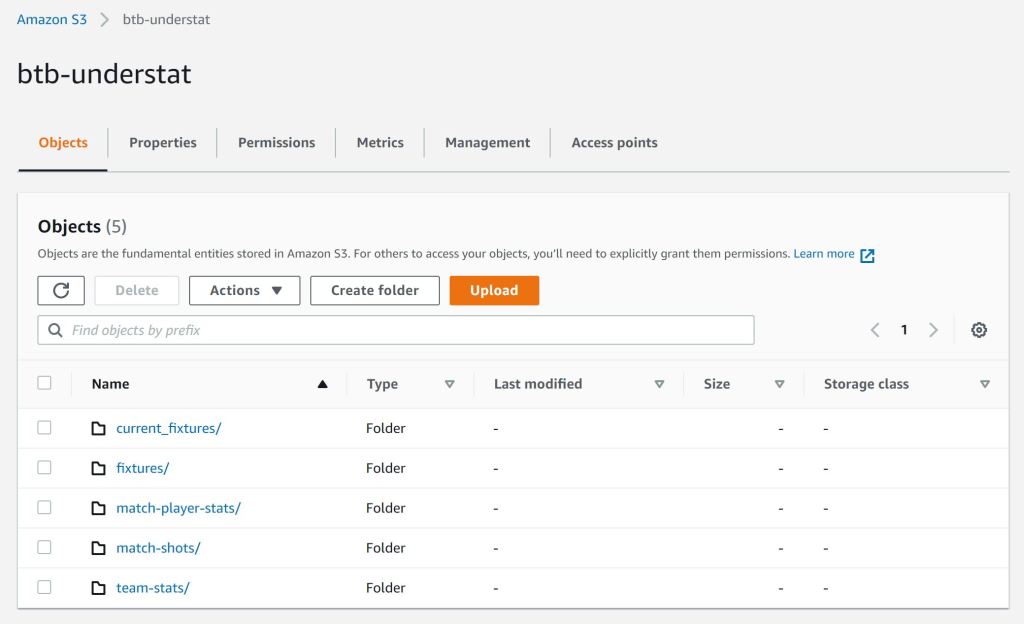
Of course a different structure is also possible. I used one bucket for each data provider. To have not many buckets, it’s also possible to have different directories in a single bucket. This just need to be adapted in the scripts I share via my GitHub account.
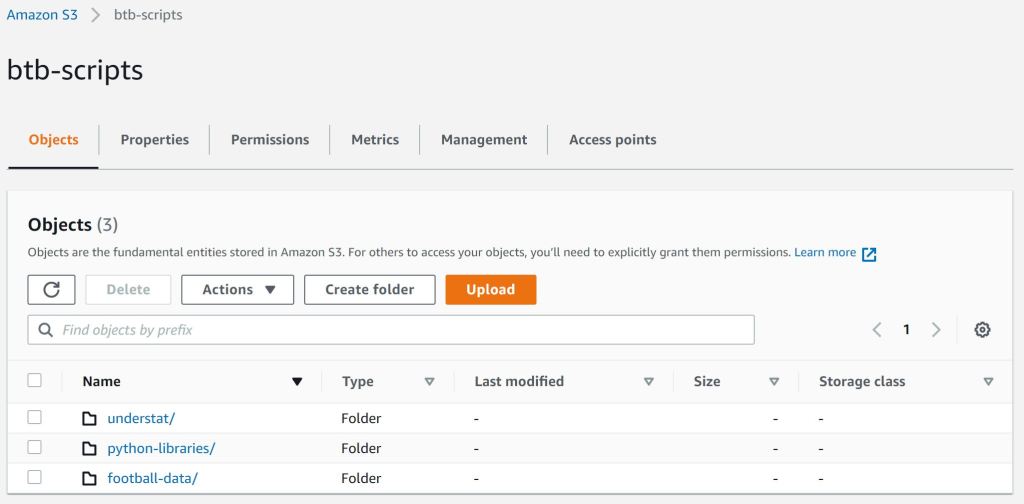
Script storage
AWS Glue uses the AWS S3 to store the different processing scripts and Python packages. Therefor an additional bucket and structure is needed. The first picture already showed the btb-scripts bucket, which I created for this purpose. I organized the scripts by each data provider and a shared directory for the single Python packages.
Resource permissions
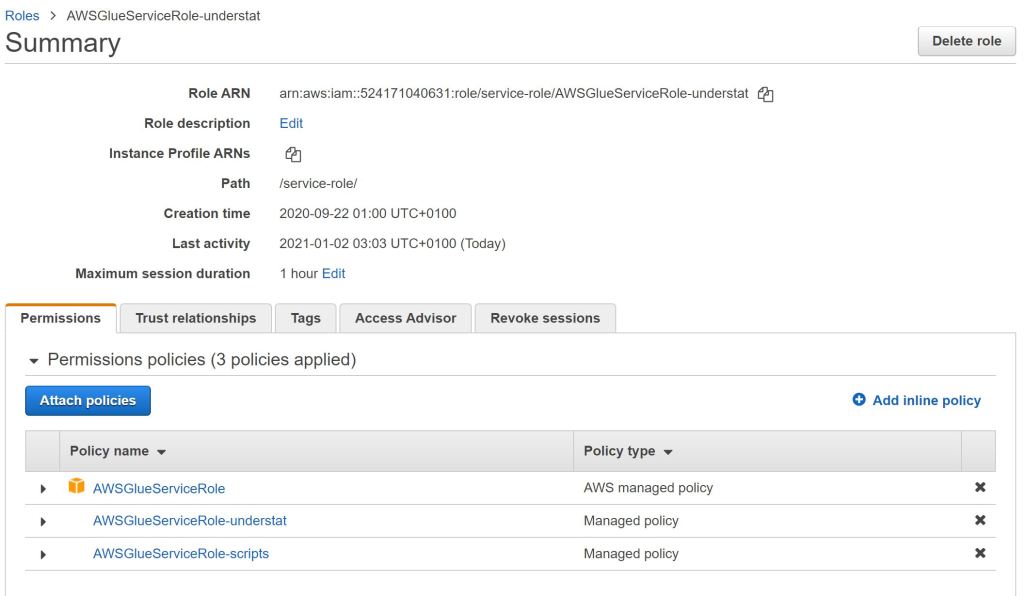
The AWS IAM service (Identity and Access Management) is used to manage all access permission for the different AWS resources and services. When processing data with AWS Glue, the single Glue Jobs need to have access to the data buckets and the script buckets. Therefor a resource policy need to be created for each created bucket.
The IAM service provides you the possibility to create policies. This can be done via a user guide or by defining the policy as a JSON:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::btb-understat/*"
}
]
}The example defines a policy for read & write access to the understat bucket and all subdirectories. The same need to be defined for the scripts bucket, as glue also has to read and write the different scripts.
IAM roles are used to group created and existing policies. For this example, we need a AWS Glue role, which contains the resource policy for the 2 created buckets and the service policy for accessing the AWS Glue service. This one is later attached to each single AWS Glue Job.
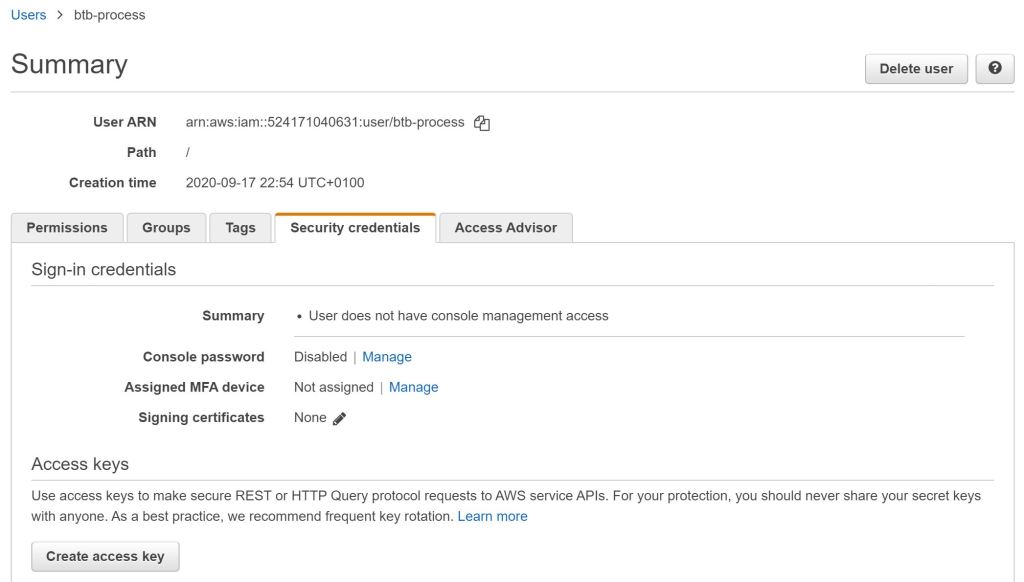
Access Keys
For calling AWS services outside the website it’s necessary to create access keys for authorization. Therefor I created a single technical user (I am using the root account for logging into AWS), which get’s all the permissions needed outside AWS (e.g. S3 full access). The security credentials for the new users offers the possibility to create a new set of access key credentials.
Create extraction jobs
All done until now, is more or less just configuration work. Now it’s time to create the jobs, which will extract the data from understat. AWS Glue Jobs are one of the most easiest ways to automate Python scripts in AWS.
For this basic processing steps Python Glue Jobs are totaly fine. If you are already familiar with Spark, it’s also possible to use Spark for the Glue Jobs. As the whole job is based on the external Python library understat, it’s required to provide the corresponding wheel files and all dependencies for the job execution. That’s done via the Python library path. All required wheel files for this example can be found in my GitHub repository.

I coded and tested all my scripts in PyCharm. AWS provides the Boto3 package, which offers the possibility to use nearly every AWS service and resource with Python. There’s also the possibility to use AWS development endpoints for Jupyter notebooks. So you could directly develop inside the AWS environment, but this service is a bit costly and that’s why I never used it.
import boto3
client = boto3.client('s3')
response = client.list_buckets()
# Output the bucket names
print('Existing buckets:')
for bucket in response['Buckets']:
print(f' {bucket["Name"]}')For each script I use two lists to control the leagues and seasons, which should be loaded during the execution. For the initial load I activated all seasons and processed the script for one league after the other. The daily load is just done for the current season, but for all leagues at once.
lst_leagues = [
"bundesliga"
,"la_liga"
,"serie_a"
,"ligue_1"
,"rfpl"
,"EPL"
]
lst_seasons = [
# {"param_season" : "2014", "directory_season" : "2014_15"},
# {"param_season" : "2015", "directory_season" : "2015_16"},
# {"param_season" : "2016", "directory_season" : "2016_17"},
# {"param_season" : "2017", "directory_season" : "2017_18"},
# {"param_season" : "2018", "directory_season" : "2018_19"},
# {"param_season" : "2019", "directory_season" : "2019_20"},
{"param_season" : "2020", "directory_season" : "2020_21"}
]While looping through the configurations lists, the values for seasons and leagues are used to build the key, where the single files are stored. I decided to create a single JSON file for each league & season combination. The sub-directories are later used to define the partitions of the tables and reduce the number of files, scanned during a query.
v_file_name = 'current_fixtures/' + season["directory_season"] + '/' + league + '/' + season["directory_season"] + '_' + league + '.json'The response of the Understat functions can easily be transfered into a Pandas data frame. And by using the AWS S3 boto3 client this data frame can be stored in the specified location. So a file for each league and season is created at the S3 bucket.
df_fixtures = pd.DataFrame(fixtures)
client.put_object(Body=bytes(df_fixtures.to_json(orient='records', lines=True).encode('UTF-8')), Bucket=v_bucket, Key=v_file_name)The scripts for each mentioned interface to Understat can again be found at my GitHub repository.
Build a workflow
After implementing all the single jobs, it’s already possible to manually load all data to the S3 bucket. But of course an automation for this would be great. AWS Glue offers ETL workflow as a possibility to orchestrate single Glue ETL jobs.
Glue workflows consist of triggers, jobs and crawlers. At first using triggers and jobs is enough. Triggers control, when and whether a job is executed. This can be by an event, on demand or, as needed in this case, via a scheduler. The trigger needs to be added first and configured.
As the starting trigger of the workflow is created, all Understat jobs can be added to the workflow. These jobs can all be executed in parallel. If there’s the requirement to execute a sequence of jobs, event based triggers need to be added between each sequence step.
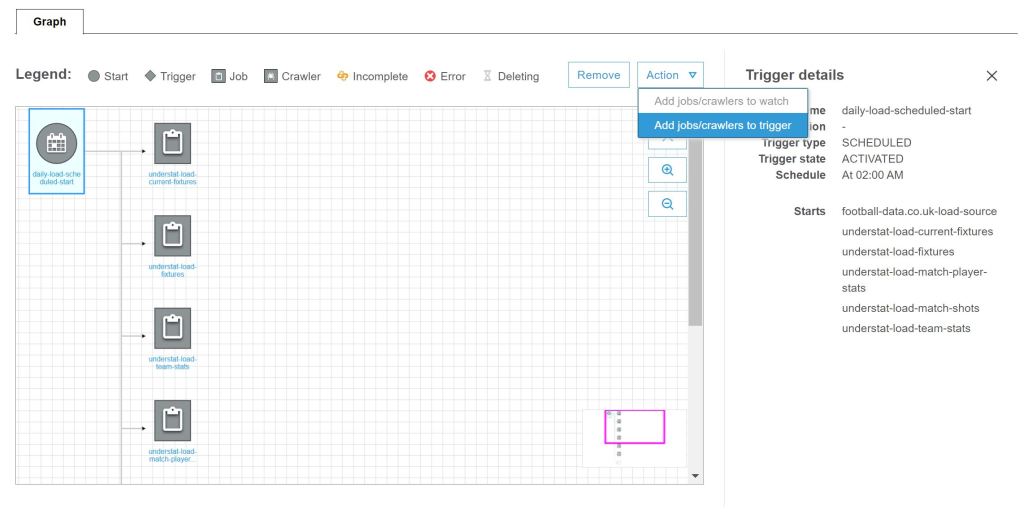
To test the complete workflow it can be triggered manually. The executions of the workflow are shown in the history. The output of the single Python jobs can be checked in the Cloudwatch service. This is the central monitoring service for the different AWS services.
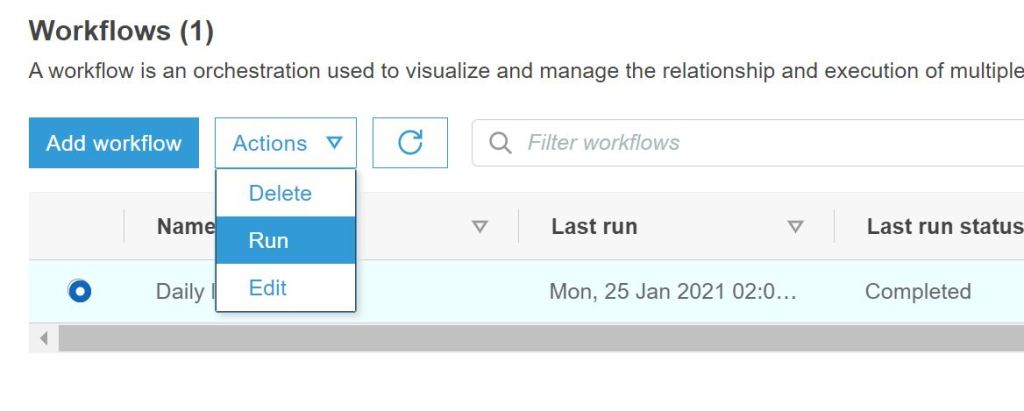
The created workflow provides all Understat data in the S3 bucket. This is the starting point to process the data and build and implement betting or predictive models. The data can be further processed with Python and the corresponding Python jobs extend the workflow.
Create the data catalog
But how is it possible to access the data for processing. It’s possible to directly read the single files from S3. But the data is highly partitioned. E.g. the match shot data consists of a single file for each match. So getting all data at once for processing can be a bit complicated. With Athena, AWS offers a query service, which provides the possibility to execute SQL statements on data stored in S3. But Athena needs a Glue data catalog providing the information for the data schemas available in S3.
Glue Crawler
The data catalog is organized in databases and tables. That’s really similar to schemas and tables in a relational database. But in comparison to a relational database these tables just define the structure of one or multiple data sources, they do not contain data. The tables are just metadata tables.
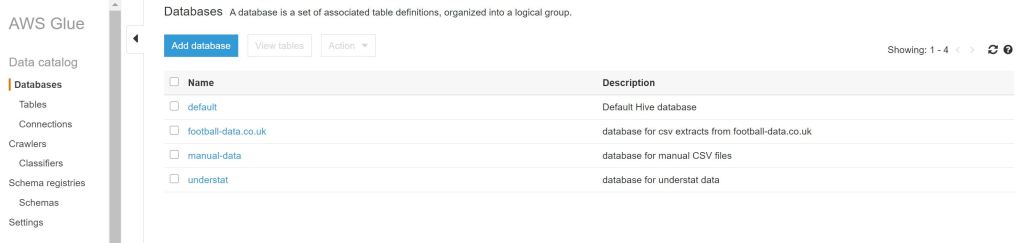
I created a single database for each datasource I used. So it’s a bit easier to maintain the increasing amount of tables. The database is needed to create and configure a data crawler for the different files as well as the IAM role, which was also created before. Beside this the most important configuration step is the path, which should scanned for table structures. It’s important to select the base directory of the single interface.

Executing the crawler will create the corresponding fixtures table in the understat database. The single fixture files were create in sub-directories for the different seasons and divisions. These sub-directories are automatically identified as partitions. Table partitions are marked as partition keys and help to increase the query performance, when only single partitions are filtered. So only a subset of files need to be read.
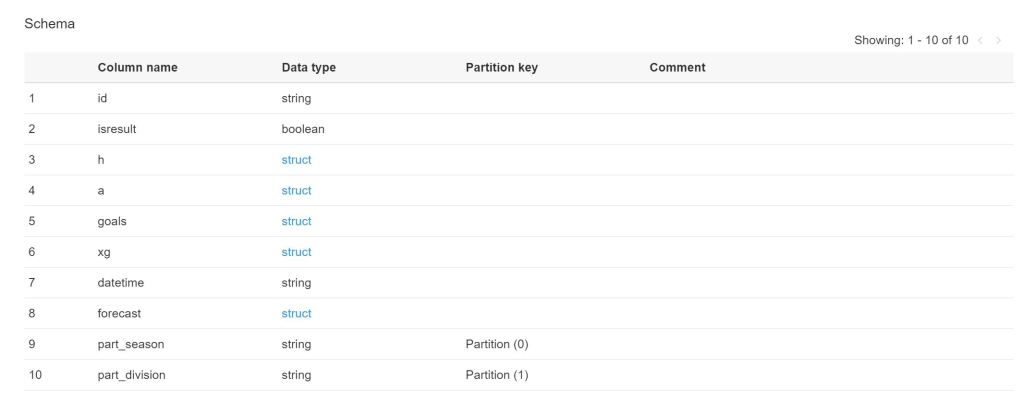
Athena query service
Personally I really like working with SQL and think, that everybody working with data should take a look at it. With Athena, AWS offers a query service, which allows you to analyse data stored in S3. The service is integrated with the Glue data catalog. So you are able to access the tables, which were created by the Crawler.
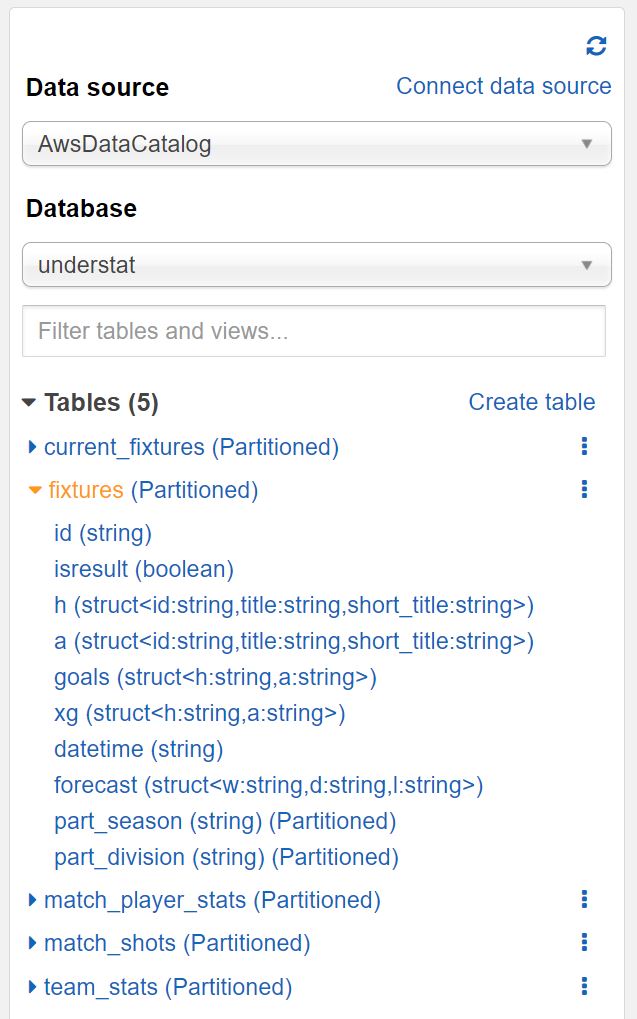
The look and feel is really similar to a normal SQL database client. But instead accessing data in a database, you are quering the different JSON files stored at a S3 bucket. The JSON structure is automatically transformed into columns. Objects and nested structures are shown as JSON values inside a column.
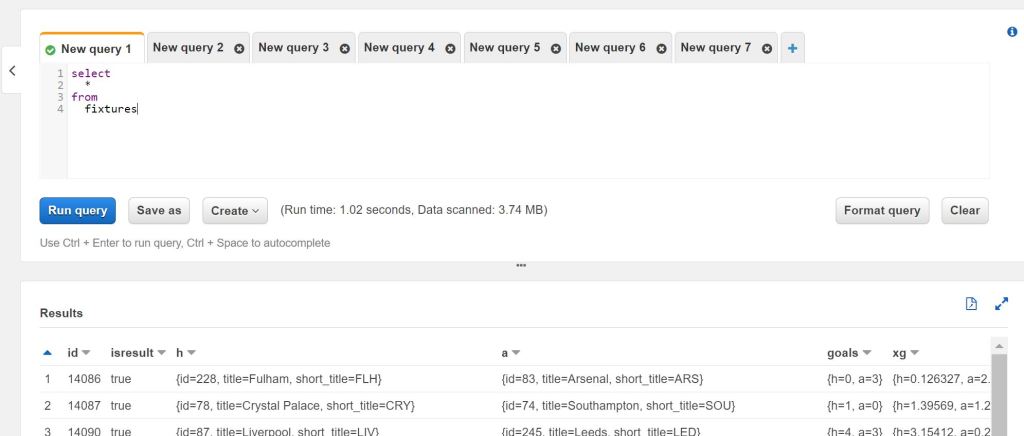
But Athena is not only a query service for data analysis and data discovery. You are also able to use it via the boto3 package in python. So it’s possible to also include SQL logic into Python Glue jobs. But that’s something I will cover in another blog.
Costs
Nothing is for free and of course also AWS wants some money for using their services. To not lose track of your monthly costs, AWS offeres the Cost Management console, where you can check your current and predicted costs per service. And you are also able to create alerts for personal budget limits.
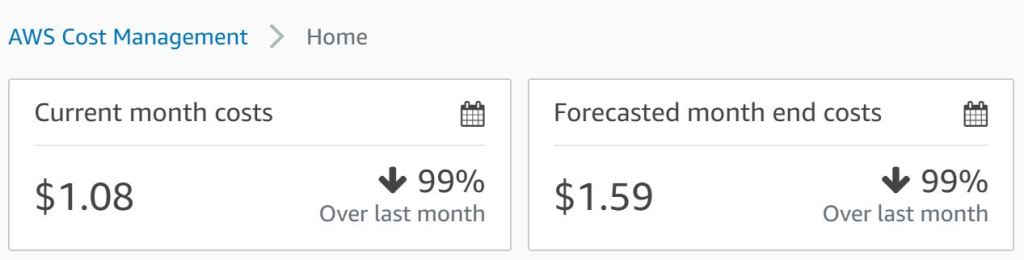
To get an impression, how much the explained automation costs, I added my cost prediction for December 2020. During this time, the Glue workflow was executed nightly every day and no other service was used. A monthly cost of 1.59$ is in my opinion really fair. You can image how much processing steps can be added and you not even reach monthly costs of 30$ or 50$. Whether is it worth to spend such amount of money is up to everybody self. It’s also important to keep in mind, that this is just for this Glue service. As soon as other services (e.g. EC2 instances) are needed, the costs can differ a lot.
Conclusion
The AWS serverless services are a great option to automate the data processing and calculations for betting models. With SQL and Python it’s possible to use well-known languages and I am able to easily migrate my existing process. Implementing the first script was pretty simple. Now it’s time to go on and move also the rest of my models to AWS. Most interesting will be the cost development, especially when also adding the Exasol database. This will be one of the decisive factore, whether AWS will be a long term solution to automate my betting models.
If you have further questions, feel free to leave a comment or contact me @Mo_Nbg
Sources:
Understat documention – https://understat.readthedocs.io/en/latest/

3 Replies to “Automate your betting models with AWS”