
The intention of this blog post, was a bit different at the beginning. At first I wanted to improve my existing ML Poisson model by adding the team market values as additional features. But as I worked on the topic, one question came more and more to the fore: Is one single model enough to BeatTheBookie?
During summer I introduced my new ML Poisson model. This model was designed in a way so it’s easily possible for me to add additional features and increase the predictive power of the model. The 2nd version of the ML Poisson model should now contain also the transfer market values. These values are scrapped from the website Transfermarkt.com.
Team market value features
The idea to use team market values as features for a predictive model is not new to me. I already did a data journey in the past, where I tested the use of market values. So using this information to increase the predictive power of my models is obvious. The feature importance test also indicated high relevance for the added market value features. So I expected an increasing profit for my model.
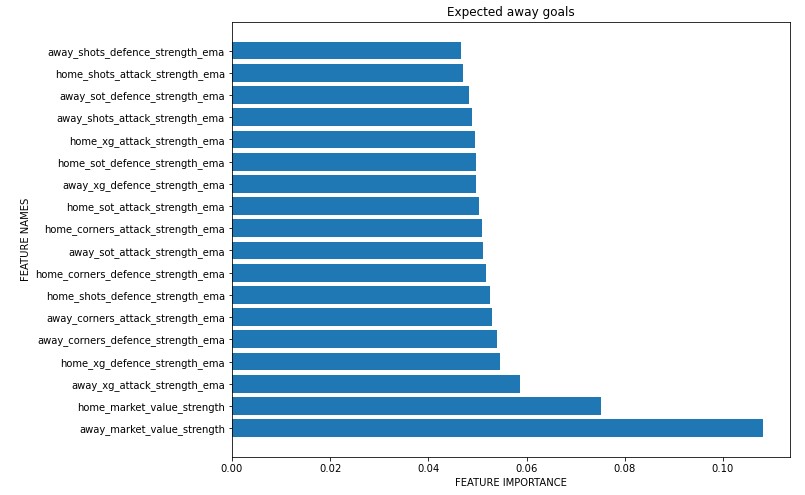

Unfortunately this was not confirmed by the model simulation. Quite the opposite. I created a bunch of different models, based on different prediction methods (regression vs. classification), different time windows (last 5 to 30 matches) and different machine learning algorithms (logistic regression, random forest). But there was no combination, which increased the performance. Models, which did not contain market value data, overall even showed a better performance. And the desire to improve especially non-performing divisions like the Serie A has taken the back seat. But what went wrong? Was my base idea wrong? Is a single model, which get’s extended step by step, not enough?

Ensemble modeling
So I started again doing some research and stumbled over another method to increase the accuracy for a predictive problem: Ensemble modeling. [1] There are different methods of ensembling models, among which staking seems the most interesting one. Stacking involves fitting many different model types on the same data and using another model to learn how to best combine the predictions.
For a first test I decided to use the predictions of 3 models. The ZIP model provides predictions based on long term goals stats. The Vanilla Poisson model is more short term oriented and based on xG data. I use both models already for a long time. The market value model was just added recently to also have a model, which provides a estimation just based on the market values. As some kind of anchor I decided to add the fair market probs. So the ensemble model could determine, where the market differs from my models. Additionally a league encoding is another feature. Each league might have specific characteristics and this feature should allow the ensemble model to respect this.

The first backsimulation tests of this model already showed some promising results. The results were so promising, that I even added draw bets and the most problematic leagues Serie A and Serie B. No model was yet able to provide profit for this kind of bets. Theres just the Championship, where the Ensemble model was not able to provide any profit. Taking a look at the profit per season is also very promising. While the old models mainly generated the profit during one season, the ensemble model provides a positiv profit for each season. That’s of course way more interesting for a professional bettor, who needs such a kind of steady profit.
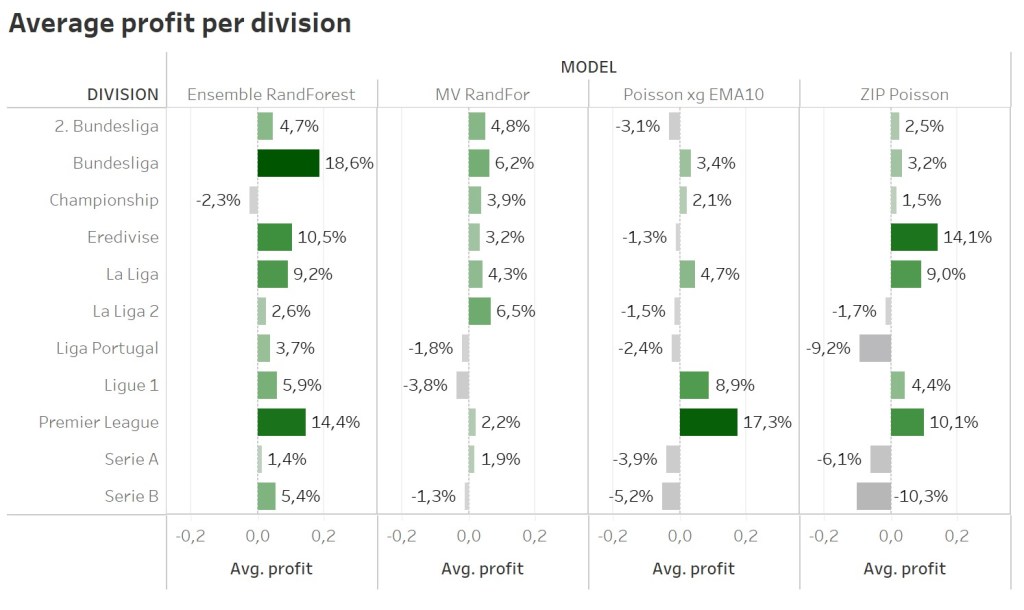
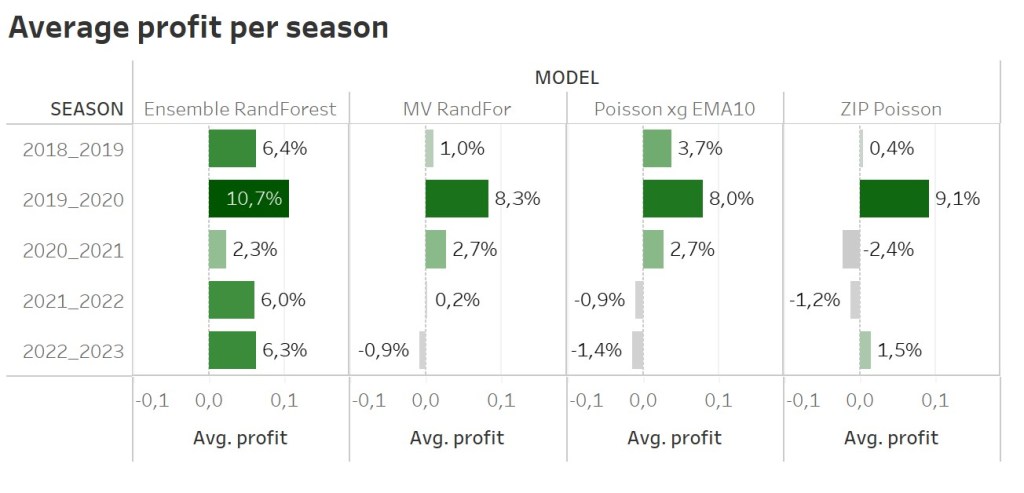
Conclusion
With my introduction of the ML Poisson model at the beginning of the season I thought one model, which you could extend step by step, would be enough to increase the predictive power. But the first tests with ensemble modeling indicate, that I was wrong. Combining different models seem to be the better way. I will continue going this road. That also means, I will provide more different models for the BeatTheBookieDataService instead of improving single models. This will start with the mentioned market value model.
If you have further questions, feel free to leave a comment or contact me @Mo_Nbg.
References:
[1] https://machinelearningmastery.com/tour-of-ensemble-learning-algorithms/
