
Before the new season will start I should take a look at the last season. Everybody following my pick history already knows: the last season again was very disappointing! But I again have to point out, that I of course did not expect to find the “holy grail” after just two seasons of model testing. So how bad do the numbers really look, and what are the most important “lesson learned” are….
Pyckio history
I really like using Pyckio to track my bets during the season. So everybody is able to follow my picks and I have a total transparency about my unsuccessful models and maybe onetime about a successful model. The Pyckio profit line looked really good at the beginning of the season. But since mid of December I suffered a very very hard losing streak. Overall my model suggested 181 bets, which resulted in an overall profit of -32,6 units and a yield of -3,6% while using a 5 unit flat stack. These results differ from the model simulations as I not only used the 1×2 markets, but also the Asian handicap markets, when my model suggest e.g. a draw and a away win. Doing this absorbed the losing streak a bit, but of course would have also shortened the profit, if the bets would have been successful.


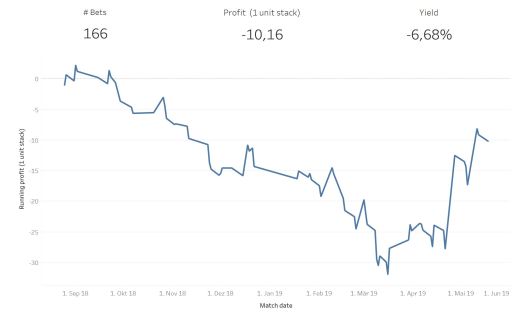
Poisson model
Even if I did not use my Poisson model during the last season, I would like to mention it, for comparison as it suffers the same problem like my Team Strength MLP model does. The simulation selected 166 bets with an overall Yield of -6,68%.
Team strength MLP
The Team strength MLP simulation looks even worth. The loss is twice as high. 188 bets were select with a stunning overall yield of -12,43%. That’s really bad and I think the result could not look worse using on random bets. That’s also the first season the Poisson model performed better than the Team Strength MLP. During the backtest my MLP was superior.

Form over- & underestimation
During my test phases with the Poisson model and my Team Strength MLP I recognized one big disadvantage of both my model implementations: Beside their normal average performance football teams also have a short term performance. This short term performance in the most extreme case could vary from match to match. And a predictive model should respect this. But unfortunately my models don’t do this.
This year during each match day I created a form factor for each match to get an impression, whether my model over- or underestimates the short term form of the last 6 matches. As a reference I used the Pinnacle odds assuming the market already implies the short term form.
To calculate the match form factor, I assigned the home team for each win in the last 6 home matches a +1 and a -1 for a lose. A draw was counted as zero. The same was done for the away team, just for the last 6 away matches. The sum of both results is the match form factor. The higher the match form factor, the better the form of the home team in comparison to the away team and vice versa.
Following pictures clearly show, that my model always underestimates the team with the better short term form. When the form of the home team was really good (positive match form factor), the market odds most of the times were shorter. Despite the small sample size this looks not good.


So my next model definitely needs some kind of time context to maybe identify and learn such performance trends. Therefor I will test a model based on financial trading indicator Moving Average Convergence Divergence (MACD). I hope that could be a solution to train a neural network to identify such performance trends.
Team market value
The last season Schalke played really bad. They had to fight hard against the relegation. Matches against other opponents also fighting against relegation, provide another “lesson lerned”: Get more data!
My model often predicted such matches relative even because of an identical form. But the market favored Schalke. But why? What’s the difference between, let’s say, Schalke & Augsburg? It’s the market value or team value:
- Market value Schalke 04 2018/19: 243 mill
- Market value Augsburg 2018/19: 100 mill
This is a feature I should definitely add to my model. The correlation test was already positiv.
If you have further questions, feel free to leave a comment or contact me @Mo_Nbg.
