
In the first part of this data journey, I took a look at the general definition of expected goals (xG) and the usage of this metric. In the next step in the process of testing the predictive power of xG, I need to get some data. This part will focus on getting the team expected goals statistics. In one of the following parts, I will also take a look on getting the player expected goals statistics as this of course offers even deeper insights.
Getting the right tools
I already provided a guide to collect data from static websites. Unfortunately I found no static site, which provides this kind of metric. That’s why I now had to look, how I am able to scrap data from dynamic web pages. In comparison to static websites dynamic pages are rendered on the clients web browser and not on the server. So we need a possibility to emulate a browser in Python. Selenium offers exactly such functionality. It’s a package for web-based automation and testing.
pip install selium
Additional to Selenium I installed the chromedriver. I am using Chrome for the following script.
conda install -c conda-forge python-chromedriver-binary
Together with the BeautifulSoup package you are able to scrap a web page as it is a static side with one small extension: it’s possible to click buttons and navigate through the site.
import urllib.request import chromedriver_binary from bs4 import BeautifulSoup as bs from selenium import webdriver
I always execute Chrome in headless mode, so that the browser window itself does not need to be rendered. But while testing a script it could also be helpful to see actually, what is happening in the browser.
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("window-size=1024,768")
chrome_options.add_argument("--no-sandbox")
Understanding the website structure
Therefor you have to understand the site structure und order of actions needed to get all the data you need. I used the site Understat.com to get xG data. This site offers detailed statistics on match and player level for the Big5 and the Russian league. Starting point for each league is page containing the current fixtures, table and player stats. There you can select the specific season, which is basically just another URL, and switch between all weeks of a season.
This site contains already the overall result and the xG values. But I want to get some more detailed stats, which can be found in the detailed match page with a statistics tab.
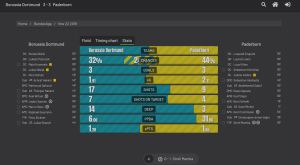
These are all pages needed to get the xG data for each match, season and league. All you need to do is think about the logic reading all matches of a season.
Scrap the data
At first you have to define the URL and load the main page of one season and league. In this example, we are loading the current season of the Bundesliga.
# define URL v_url = 'https://understat.com/league/Bundesliga/2019' # Initialize a new browser browser = webdriver.Chrome(chrome_options=chrome_options) browser.get(v_url)
The “Previous Button” is needed to walk backwards through all week of a season
prev_button = browser.find_element_by_class_name('calendar-prev')
Update:
Understat changed the first week shown in the league overview. This may be also the 1st instead of the current week in a season. So the scrapper needs to be able to go forward and backwards in weeks. I adapted the Python script and uploaded a new version to GitHub.
The loop itself is a bit more complex. You not only have to loop over all weeks, the problem is the exit criteria. When you reach the first week of a season, the previous button is disabled, but you still have to do another loop, as you also want to get this week.
#loop control is handled inside the loop
do_loop = True
last_loop = False
#loop as long prev button is enabled
while do_loop == True:
#
#later: read the single match data
#
#click button for next dates
prev_button.click()
#Check loop criteria
#- as long more weeks for the season are existing - button is enabled
#- first week in the season
if not(prev_button.is_enabled()) and last_loop == True:
do_loop = False
# when no more weeks are available - last loop for last week
if not(prev_button.is_enabled()) and last_loop == False:
last_loop = True
print('last loop set')
To get the single matches for a single week, you have to select all elements with the class “calendar-game”.
v_matches = v_date.find_elements_by_class_name('calendar-game')
If a match is finished a has a result, you can get the match URL to scrap the detailed match statistic.
#loop over matches
for v_match in v_matches:
v_match_info = v_match.find_element_by_class_name('match-info')
#get link match info, if match has already a result
if v_match_info.get_attribute('data-isresult') == 'true':
v_match_href = v_match_info.get_attribute('href')
This is done by just opening a new browser with the extracted URL. The sleep is added, as I multiple time faced the problem, that not yet all data was loaded and my script already continued.
browser_match = webdriver.Chrome(chrome_options=chrome_options) browser_match.get(v_match_href) #sleep as sometimes not all data is time.sleep(2)
After the match site was loaded, the tab with the match statistics has to be clicked. This tab has be identified by the label and an additional attribute.
#stat label has to be click, so that schema with
#statistics can be read
schema_buttons = browser_match.find_elements_by_tag_name('label')
for schema_button in schema_buttons:
if schema_button.get_attribute('for') == 'scheme3':
schema_button.click()
The single tabs on the page have the class “scheme-block”. The specific scheme block with the attribute ‘data-scheme’ = ‘stats’ is exactly the one, containing the detailed statistics, you have seen in the screenshot.
#get schema blocks
v_schema_blocks = browser_match.find_elements_by_class_name('scheme-block')
#loop over all schema blocks,
#but only the stats schema block is interesting
for v_schema_block in v_schema_blocks:
if v_schema_block.get_attribute('data-scheme') == 'stats':
Now we have finally reached the point, where we are able to extract the stats of the match. Understat offers following statistics for every single match:
- Goals
- Expected goals
- Shots
- Shots on target
- Successful passes in the last 3rd
- Passes allowed per defensive action in the opposite half
- Expected points
#get single stats lines
v_stat_lines = v_schema_block.find_elements_by_class_name('progress-bar')
#loop over single stat lines
for v_stat_line in v_stat_lines:
#differ between interesting stat lines
if v_stat_line.find_element_by_class_name('progress-title').text == 'TEAMS':
v_home_team = v_stat_line.find_element_by_class_name('progress-home').text
v_away_team = v_stat_line.find_element_by_class_name('progress-away').text
if v_stat_line.find_element_by_class_name('progress-title').text == 'GOALS':
v_home_goals = v_stat_line.find_element_by_class_name('progress-home').text
v_away_goals = v_stat_line.find_element_by_class_name('progress-away').text
if v_stat_line.find_element_by_class_name('progress-title').text == 'xG':
v_home_xgoals = v_stat_line.find_element_by_class_name('progress-home').text
v_away_xgoals = v_stat_line.find_element_by_class_name('progress-away').text
if v_stat_line.find_element_by_class_name('progress-title').text == 'SHOTS':
v_home_shots = v_stat_line.find_element_by_class_name('progress-home').text
v_away_shots = v_stat_line.find_element_by_class_name('progress-away').text
if v_stat_line.find_element_by_class_name('progress-title').text == 'SHOTS ON TARGET':
v_home_shots_on_target = v_stat_line.find_element_by_class_name('progress-home').text
v_away_shots_on_target = v_stat_line.find_element_by_class_name('progress-away').text
if v_stat_line.find_element_by_class_name('progress-title').text == 'DEEP':
v_home_deep = v_stat_line.find_element_by_class_name('progress-home').text
v_away_deep = v_stat_line.find_element_by_class_name('progress-away').text
if v_stat_line.find_element_by_class_name('progress-title').text == 'PPDA':
v_home_ppda = v_stat_line.find_element_by_class_name('progress-home').text
v_away_ppda = v_stat_line.find_element_by_class_name('progress-away').text
if v_stat_line.find_element_by_class_name('progress-title').text == 'xPTS':
v_home_xpts = v_stat_line.find_element_by_class_name('progress-home').text
v_away_xpts = v_stat_line.find_element_by_class_name('progress-away').text
Store the data
As you may already have noticed in older posts, I always import my data into a Exasol database. For me it’s just easier to analyse and visualize data with help of SQL. That’s why I of course also import this data into my database. The steps are always the same.
The SQL script to create the sandbox table can be found on GitHub. I added already some columns, which are needed later, when I add this webscraper to my daily loading process. Automation is the key… 😉
Inside the Python script you have to connect to the database.
import pyexasol #build db connection Con = pyexasol.connect(dsn='192.168.164.130:8563', user='sys', password = 'exasol', schema = 'sandbox', compression=True)
The created data dictionary with the match statistics can easily be imported into the Sandbox table.
#import data frame to db Con.import_from_iterable(df_data,'understat_match_team_stats')
Importing the data does not take long. But you should get yourself some hours to scrap all seasons. Loading each individual match detail page takes some time. This should of course be considered, when using such a web scraper for a regular processing. That’s why I already added a week limiter to the final script.
You can find the complete Python script of the described webscrapper at GitHub:
GitHub – Python Understat match stats web scrapper
If you have further questions, feel free to leave a comment or contact me @Mo_Nbg
Sources:
https://dev.to/googlecloud/using-headless-chrome-with-cloud-run-3fdp

4 Replies to “xG data journey – scrapping dynamic webpages”