
Some days ago I extended my ZIP Poisson model by some additional leagues. These are: Championship, Seria B, La Liga 2, Eredivise, Liga Portugal. It’s always helpful to be able to select more possible bets. Playing more bets reduces the variance of your hit rate and provides a more stable average profit. So let’s have a look, how the ZIP Poisson model performs including the new leagues.
Continue reading “ZIP model performance incl. minor leagues”Season 2022/23 – A sobering beginning
In the past I already posted some summaries in my pick history for different models. So everybody could get an impression, how a real life betting using my models could look like and to test, whether the profit, indicated by the backtesting, can also be reached in the future. With this post I want to start such a series again for my ML Poisson model and additionally compare it to the performance of the other models. So let’s start…
Continue reading “Season 2022/23 – A sobering beginning”Inflated ML Poisson model to predict football matches
My last blog post “Poisson vs Reality” did change something in my head. I realized, that I not yet checked single parts of my model enough, whether they differ from reality and whether I could reduce this difference and improve the model performance. That’s why I started creating a new model approach for the new season and focus on the improvement of single steps during the model process. After the training of multiple models, I will test against the fair profit, which kind of adaptions improve a Poisson distribution model the most.
Continue reading “Inflated ML Poisson model to predict football matches”Poisson vs Reality
The Poisson distribution is widely used to predict the result of a football matches. Multiple articles can be found in the internet and I also already provided a comparison of different Vanilla Poisson models. But the Poisson distribution as some limitations. The Poisson distribution assumes the number of goals a team scores are independent. But everybody watching football knows, that a team being one goals behind is way more motivated to score a goal in comparison to being already 4 goals behind. So let’s have a look how a simple Poisson distribution compares to the actual scored goals.
Continue reading “Poisson vs Reality”Why is it so hard to beat the Bookie?
Image you see following picture for two different profit lines. Both betting simulations are based on the same stacking method: Each identified value bet is set with 1 unit flat stack. Which of both simulation would you prefer? I think the answer is easy.
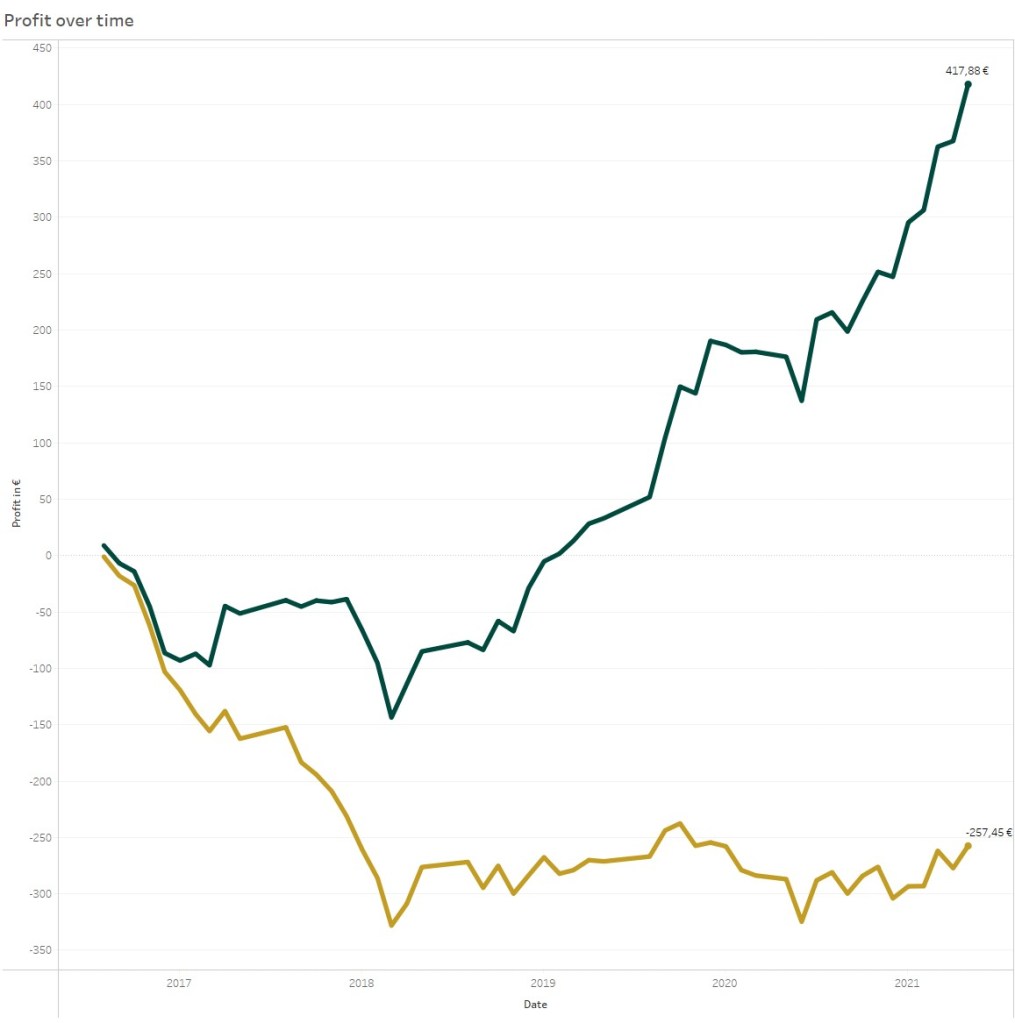
Of course everybody would prefer the green proft line. But both profit lines are based on the same predictive model. All predictions and bet selections are based on the EMA10 Vanilla Poisson xG model, which I already used for multiple blogs.
The difference between both lines: The yellow line represents the betting profit, when betting against the provided odds of a bookie. The green line represent the betting profit, when betting against a bookie without the bookie margin. This bookmaker margin eat up the whole advantage of the model.
Betting with numbers – How I select my bets
Of course I don’t write all these blogs and create the different models just for fun. Of course I am using my data and my models for betting. So I thought, it would be a good idea to explain my process of selecting bets based on my predictions.
Continue reading “Betting with numbers – How I select my bets”Scoring functions vs. betting profit – Measuring the performance of a football betting model
“What’s the best model?” – That’s a very important questions, when creating, training and testing new predictive models for football. Various machine learning algorithms and packages offer by default a set of scoring functions like accuracy, log-loss, brier score or ROC-AUC, which measure the accuracy of a probabilistic prediction. But I already recognized in older posts, that the best model based on a scoring function, was not always the best model, when it’s about using the prediction results for betting. So let’s have a look and compare the rank of some scoring functions in comparison to the betting profit of some models.
Continue reading “Scoring functions vs. betting profit – Measuring the performance of a football betting model”Using xG & advanced stats to predict football matches
With the BeatTheBookieDataService in place it’s also time to provide some new models. This post will take a look at possible models using the team statistics provided for each match by understat.com. Therefor I will compare 3 of the most used machine learning algorithms. Beside this, it’s also time to test again some basics for predictiv modeling for football: “To differ between home/away performance or not to differ”? For my Poisson models I always differed between home and away performance. But is this also needed, when using ML algorithms?
Continue reading “Using xG & advanced stats to predict football matches”The predictive power of xG – Predicting football matches with Expected Goals
“Goals are the only statistic, which decide a match” – sentences like this appeared not only once, while reading discussion about the latest xG statistics of single matches on Twitter. Even if the statistic xG is more and more used by sport journalists and during broadcasts, the meaning and importance of the statistic is not yet widely understood. This might be caused by the usage of xG for single matches or single shots. The final result of a match and the corresponding xG values might differ a lot. But over the long-term xG is a statistic, which tells us way more about a football team than goals and shots alone. To prove this, this post will take a look at the predictive power of xG in comparison to goals. The more information a statistic contains the more it should help us to predict the result of future matches.
Continue reading “The predictive power of xG – Predicting football matches with Expected Goals”Running Exasol on AWS
Automating data pipelines in AWS was just the first step of moving my betting models into the cloud. Nearly all my calculations were done in a Exasol database and I also want to keep them in a database. So I need to host one in my AWS account. For such use-cases AWS offers virtual EC2 instances. This blog will explain the single steps how to install an Exasol DB in AWS.
Continue reading “Running Exasol on AWS”
You must be logged in to post a comment.